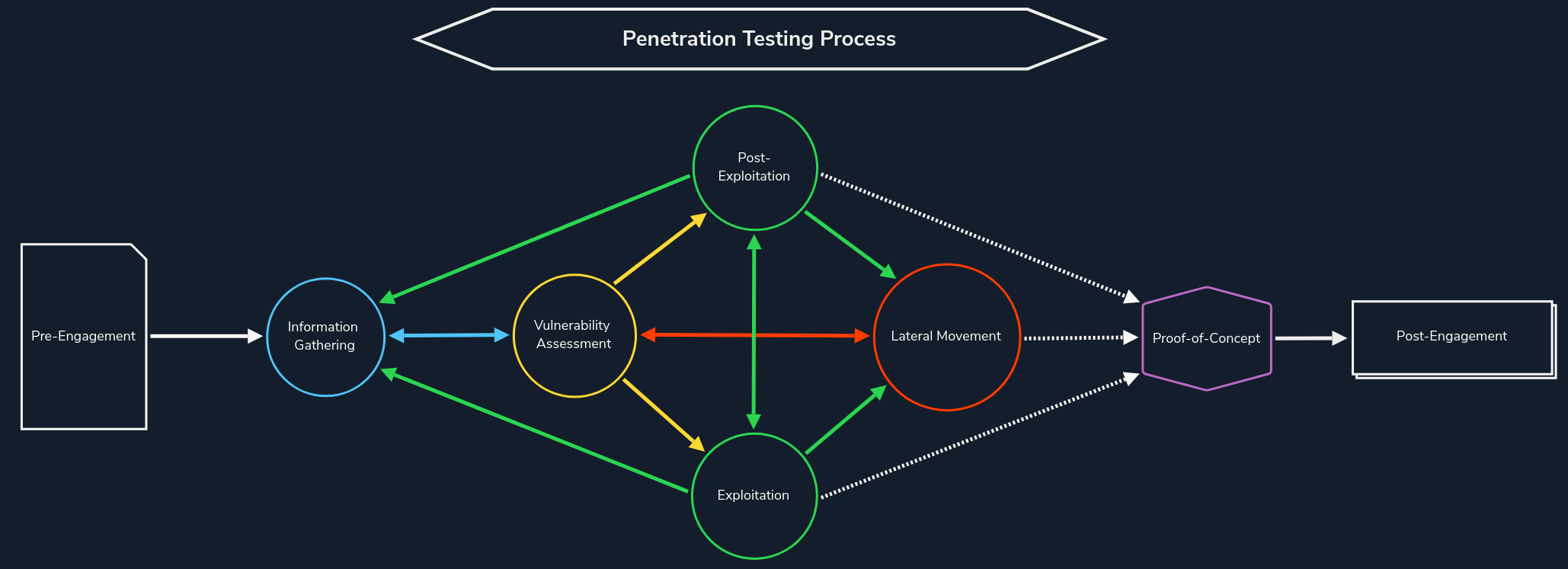
Information Gathering
信息收集阶段是每次渗透测试的第一步,我们需要在没有目标组织内部信息的情况下模拟外部攻击者。
例如,我们可以将其视为在基于SSL证书的渗透测试中偶然发现新子域。然而,如果我们仔细观察这些子域,我们经常会看到与主要公司网站不同的技术在使用。子域和vhosts用于呈现其他信息,并执行与主页分离的其他任务。因此,必须了解使用了哪些技术,它们有什么用途,以及它们是如何工作的。在此过程中,我们的目标是从以下领域尽可能多地识别信息:
- 域和子域
- IP范围
- 基础设施
- 虚拟主机
WHOIS
WHOIS域查找允许我们检索已注册域的域名信息。互联网名称与数字地址分配机构(ICANN)要求经认证的注册商在注册域名后立即在Whois数据库中输入持有人的联系信息、域名的创建和有效期以及其他信息。简单地说,Whois数据库是目前全球注册的所有域名的可搜索列表。 WHOIS查找最初是使用命令行工具执行的。如今,存在许多基于web的工具,但命令行选项通常使我们能够最大限度地控制查询,并帮助过滤和排序结果输出。Sysinternals WHOIS for Windows或Linux WHOIS命令行实用程序是我们收集信息的首选工具。然而,我们也可以使用一些在线版本,如 whois.domaintools.com。
Tanin@htb[/htb]$ whois $TARGET
从这个输出中,我们收集了以下信息:
DNS
Nslookup & DIG
我们来看看Nslookup命令行实用程序。让我们假设一位客户要求我们进行外部渗透测试。因此,我们首先需要熟悉它们的基础设施,并确定哪些主机是可以公开访问的。我们可以使用不同类型的DNS请求来找到这一点。使用Nslokup,我们可以在互联网上搜索域名服务器,并向他们询问有关主机和域的信息。尽管该工具有两种模式,交互式和非交互式,但我们将主要关注非交互式模块。 我们只需提交域名就可以查询A记录。但是我们也可以使用-query参数来搜索特定的资源记录。例如:
Tanin@htb[/htb]$ nslookup $TARGET
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
Name: facebook.com
Address: 31.13.92.36
Name: facebook.com
Address: 2a03:2880:f11c:8083:face:b00c:0:25de
如果需要,我们还可以通过在命令中添加@<nameserver/IP>来指定名称服务器。与nslookup不同,DIG向我们展示了一些更重要的信息。
Tanin@htb[/htb]$ dig facebook.com @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> facebook.com @1.1.1.1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 58899
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;facebook.com. IN A
;; ANSWER SECTION:
facebook.com. 169 IN A 31.13.92.36
;; Query time: 20 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Mo Okt 18 16:03:17 CEST 2021
;; MSG SIZE rcvd: 57
条目以完整的域名开始,包括最后一个点。在必须再次请求信息之前,该条目可以在高速缓存中保持169秒
Querying: A Records for a Subdomain
Tanin@htb[/htb]$ export TARGET=www.facebook.com
Tanin@htb[/htb]$ nslookup -query=A $TARGET
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
www.facebook.com canonical name = star-mini.c10r.facebook.com.
Name: star-mini.c10r.facebook.com
Address: 31.13.92.36
Querying: A Records for a Subdomain
Tanin@htb[/htb]$ dig a www.facebook.com @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> a www.facebook.com @1.1.1.1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 15596
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;www.facebook.com. IN A
;; ANSWER SECTION:
www.facebook.com. 3585 IN CNAME star-mini.c10r.facebook.com.
star-mini.c10r.facebook.com. 45 IN A 31.13.92.36
;; Query time: 16 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Mo Okt 18 16:11:48 CEST 2021
;; MSG SIZE rcvd: 90
Querying: PTR Records for an IP Address
Tanin@htb[/htb]$ nslookup -query=PTR 31.13.92.36
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
36.92.13.31.in-addr.arpa name = edge-star-mini-shv-01-frt3.facebook.com.
Authoritative answers can be found from:
Tanin@htb[/htb]$ dig -x 31.13.92.36 @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> -x 31.13.92.36 @1.1.1.1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 51730
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;36.92.13.31.in-addr.arpa. IN PTR
;; ANSWER SECTION:
36.92.13.31.in-addr.arpa. 1028 IN PTR edge-star-mini-shv-01-frt3.facebook.com.
;; Query time: 16 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Mo Okt 18 16:14:20 CEST 2021
;; MSG SIZE rcvd: 106
Querying: ANY Existing Records
Tanin@htb[/htb]$ export TARGET="google.com"
Tanin@htb[/htb]$ nslookup -query=ANY $TARGET
Server: 10.100.0.1
Address: 10.100.0.1#53
Non-authoritative answer:
Name: google.com
Address: 172.217.16.142
Name: google.com
Address: 2a00:1450:4001:808::200e
google.com text = "docusign=05958488-4752-4ef2-95eb-aa7ba8a3bd0e"
google.com text = "docusign=1b0a6754-49b1-4db5-8540-d2c12664b289"
google.com text = "v=spf1 include:_spf.google.com ~all"
google.com text = "MS=E4A68B9AB2BB9670BCE15412F62916164C0B20BB"
google.com text = "globalsign-smime-dv=CDYX+XFHUw2wml6/Gb8+59BsH31KzUr6c1l2BPvqKX8="
google.com text = "apple-domain-verification=30afIBcvSuDV2PLX"
google.com text = "google-site-verification=wD8N7i1JTNTkezJ49swvWW48f8_9xveREV4oB-0Hf5o"
google.com text = "facebook-domain-verification=22rm551cu4k0ab0bxsw536tlds4h95"
google.com text = "google-site-verification=TV9-DBe4R80X4v0M4U_bd_J9cpOJM0nikft0jAgjmsQ"
google.com nameserver = ns3.google.com.
google.com nameserver = ns2.google.com.
google.com nameserver = ns1.google.com.
google.com nameserver = ns4.google.com.
google.com mail exchanger = 10 aspmx.l.google.com.
google.com mail exchanger = 40 alt3.aspmx.l.google.com.
google.com mail exchanger = 20 alt1.aspmx.l.google.com.
google.com mail exchanger = 30 alt2.aspmx.l.google.com.
google.com mail exchanger = 50 alt4.aspmx.l.google.com.
google.com
origin = ns1.google.com
mail addr = dns-admin.google.com
serial = 398195569
refresh = 900
retry = 900
expire = 1800
minimum = 60
google.com rdata_257 = 0 issue "pki.goog"
Authoritative answers can be found from:
Querying: TXT Records
Tanin@htb[/htb]$ export TARGET="facebook.com"
Tanin@htb[/htb]$ nslookup -query=TXT $TARGET
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
facebook.com text = "v=spf1 redirect=_spf.facebook.com"
facebook.com text = "google-site-verification=A2WZWCNQHrGV_TWwKh6KHY90tY0SHZo_RnyMJoDaG0s"
facebook.com text = "google-site-verification=wdH5DTJTc9AYNwVunSVFeK0hYDGUIEOGb-RReU6pJlY"
Authoritative answers can be found from:
Tanin@htb[/htb]$ dig txt facebook.com @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> txt facebook.com @1.1.1.1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 63771
;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;facebook.com. IN TXT
;; ANSWER SECTION:
facebook.com. 86400 IN TXT "v=spf1 redirect=_spf.facebook.com"
facebook.com. 7200 IN TXT "google-site-verification=A2WZWCNQHrGV_TWwKh6KHY90tY0SHZo_RnyMJoDaG0s"
facebook.com. 7200 IN TXT "google-site-verification=wdH5DTJTc9AYNwVunSVFeK0hYDGUIEOGb-RReU6pJlY"
;; Query time: 24 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Mo Okt 18 16:17:46 CEST 2021
;; MSG SIZE rcvd: 249
Querying: MX Records
Tanin@htb[/htb]$ export TARGET="facebook.com"
Tanin@htb[/htb]$ nslookup -query=MX $TARGET
Server: 1.1.1.1
Address: 1.1.1.1#53
Non-authoritative answer:
facebook.com mail exchanger = 10 smtpin.vvv.facebook.com.
Authoritative answers can be found from:
Tanin@htb[/htb]$ dig mx facebook.com @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> mx facebook.com @1.1.1.1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 9392
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;facebook.com. IN MX
;; ANSWER SECTION:
facebook.com. 3600 IN MX 10 smtpin.vvv.facebook.com.
;; Query time: 40 msec
;; SERVER: 1.1.1.1#53(1.1.1.1)
;; WHEN: Mo Okt 18 16:18:22 CEST 2021
;; MSG SIZE rcvd: 68
Passive Subdomain Enumeration
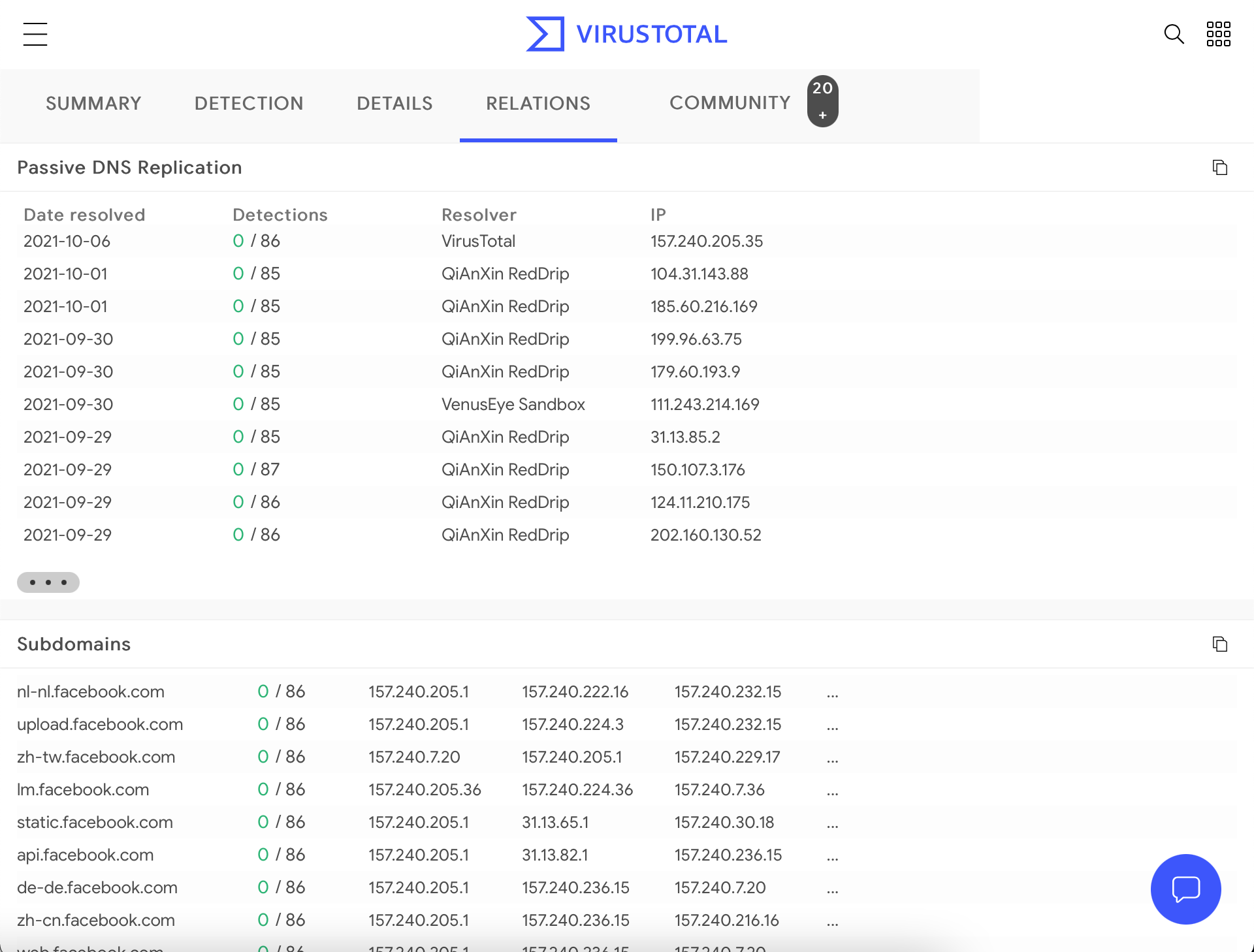
VirusTotal
VirusTotal维护其DNS复制服务,该服务是通过保留用户访问其提供的URL时所做的DNS解析来开发的。要接收有关域的信息,请在搜索栏中键入域名,然后单击“关系”选项卡。
Certificates
我们可以用来提取子域的另一个有趣的信息来源是SSL/TLS证书。主要原因是证书透明度(CT),该项目要求证书颁发机构(CA)颁发的每个SSL/TLS证书都发布在可公开访问的日志中。 我们将学习如何使用两种主要资源检查CT日志,以发现目标组织的其他域名和子域:
我们可以导航到https://search.censys.io/certificates或https://crt.sh并介绍我们目标组织的域名,开始发现新的子域。
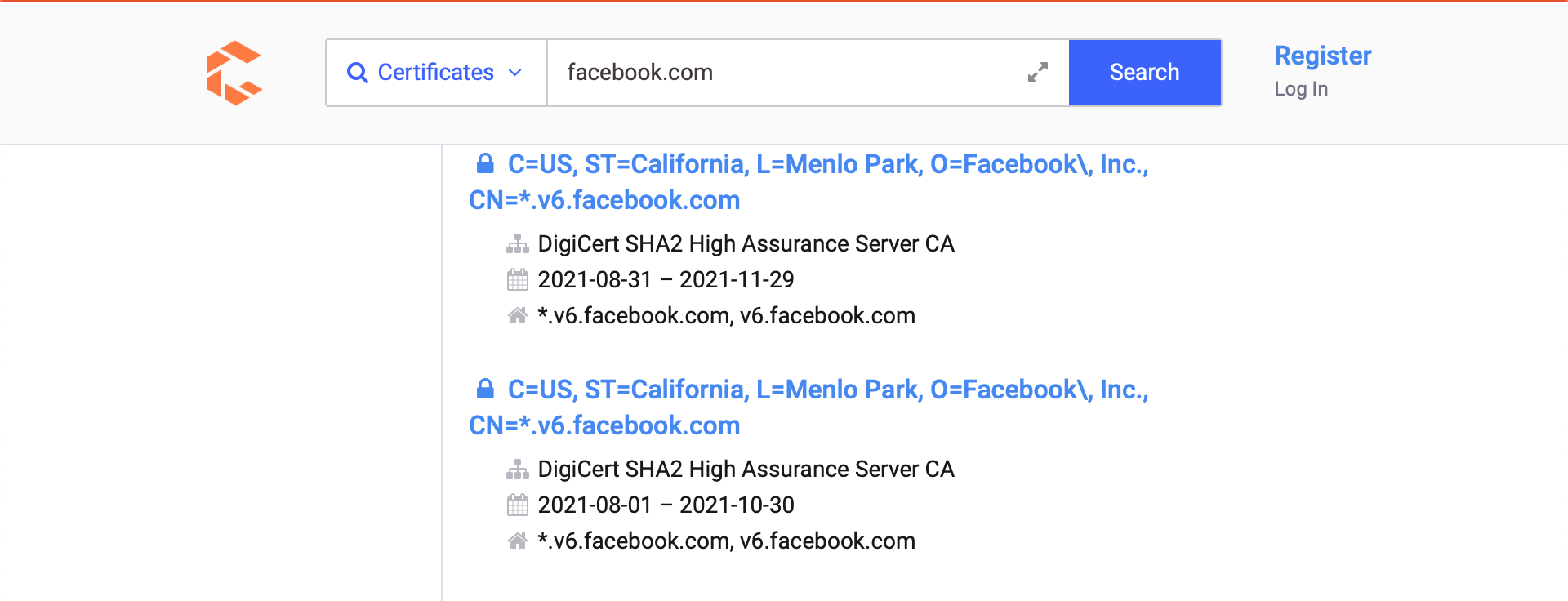
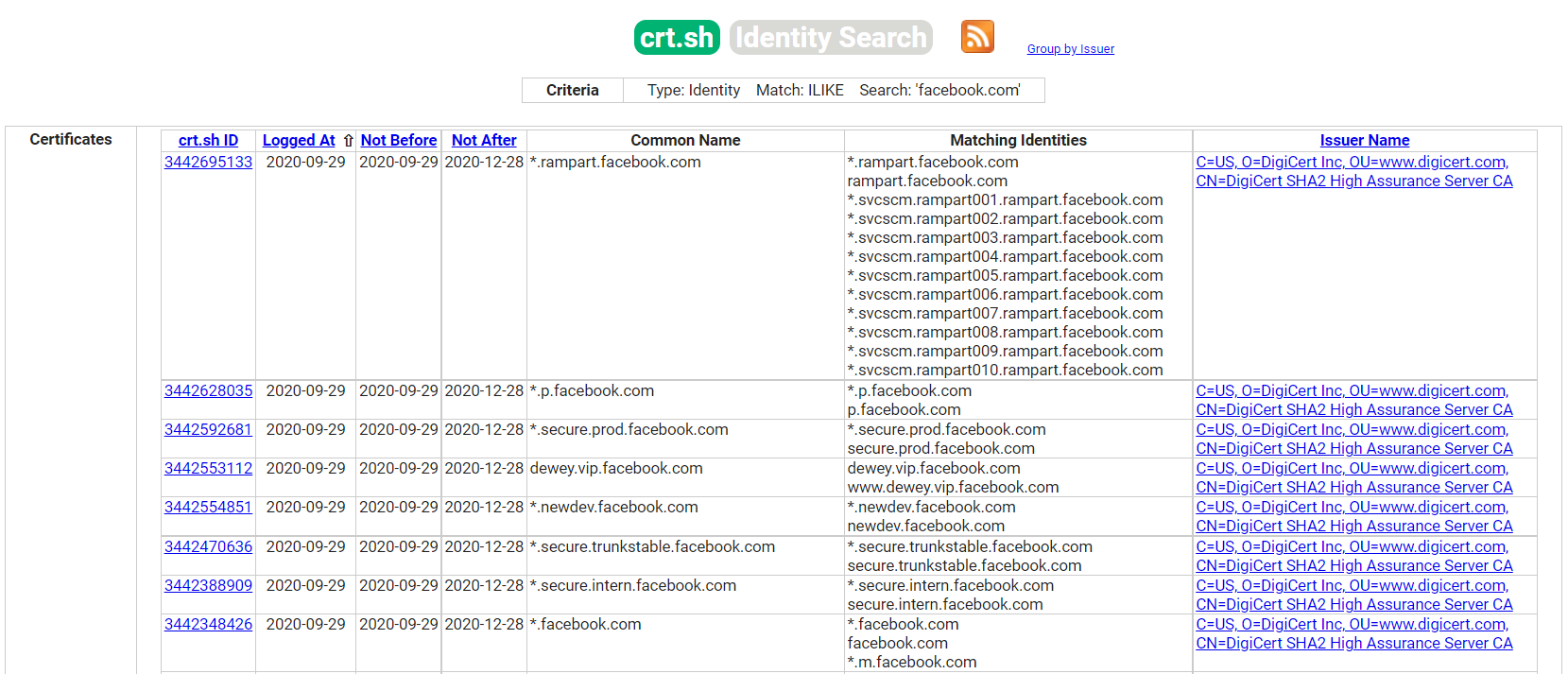
尽管该网站非常优秀,但我们希望将这些信息组织起来,并能够将其与整个信息收集过程中发现的其他来源相结合。让我们向目标网站执行一个curl请求,请求JSON输出,因为这对我们来说更易于处理。我们可以通过以下命令执行此操作:
Tanin@htb[/htb]$ export TARGET="facebook.com"
Tanin@htb[/htb]$ curl -s "https://crt.sh/?q=${TARGET}&output=json" | jq -r '.[] | "\(.name_value)\n\(.common_name)"' | sort -u > "${TARGET}_crt.sh.txt"
Tanin@htb[/htb]$ head -n20 facebook.com_crt.sh.txt
*.adtools.facebook.com
*.ak.facebook.com
*.ak.fbcdn.net
*.alpha.facebook.com
*.assistant.facebook.com
*.beta.facebook.com
*.channel.facebook.com
*.cinyour.facebook.com
*.cinyourrc.facebook.com
*.connect.facebook.com
*.cstools.facebook.com
*.ctscan.facebook.com
*.dev.facebook.com
*.dns.facebook.com
*.extern.facebook.com
*.extools.facebook.com
*.f--facebook.com
*.facebook.com
*.facebookcorewwwi.onion
*.facebookmail.com
curl -s |
Issue the request with minimal output. |
|---|---|
https://crt.sh/?q=<DOMAIN>&output=json |
Ask for the json output. |
jq -r '.[]' "\(.name_value)\n\(.common_name)"' |
Process the json output and print certificate’s name value and common name one per line. |
sort -u |
Sort alphabetically the output provided and removes duplicates. |
我们还可以通过以下方式使用OpenSSL对目标手动执行此操作:
Tanin@htb[/htb]$ export TARGET="facebook.com"
Tanin@htb[/htb]$ export PORT="443"
Tanin@htb[/htb]$ openssl s_client -ign_eof 2>/dev/null <<<$'HEAD / HTTP/1.0\r\n\r' -connect "${TARGET}:${PORT}" | openssl x509 -noout -text -in - | grep 'DNS' | sed -e 's|DNS:|\n|g' -e 's|^\*.*||g' | tr -d ',' | sort -u
*.facebook.com
*.facebook.net
*.fbcdn.net
*.fbsbx.com
*.m.facebook.com
*.messenger.com
*.xx.fbcdn.net
*.xy.fbcdn.net
*.xz.fbcdn.net
facebook.com
messenger.com
Automating Passive Subdomain Enumeration
我们已经学会了如何使用第三方服务从目标组织获取有用的信息,如子域、命名模式、备用TLD、IP范围等,而无需直接与其基础设施交互或依赖自动化工具。现在,我们将学习如何使用工具和以前获得的信息枚举子域。
TheHarvester
Harvester是一个简单易用但功能强大且有效的工具,用于早期渗透测试和红队参与。我们可以使用它来收集信息,以帮助识别公司的攻击面。该工具从各种公共数据源收集电子邮件、名称、子域、IP地址和URL,用于被动信息收集。目前,我们将使用以下模块:
为了实现自动化,我们将创建一个名为sources.txt的文件,其中包含以下内容。
Tanin@htb[/htb]$ cat sources.txt
baidu
bufferoverun
crtsh
hackertarget
otx
projecdiscovery
rapiddns
sublist3r
threatcrowd
trello
urlscan
vhost
virustotal
zoomeye
创建文件后,我们将执行以下命令从这些来源收集信息。
Tanin@htb[/htb]$ export TARGET="facebook.com"
Tanin@htb[/htb]$ cat sources.txt | while read source; do theHarvester -d "${TARGET}" -b $source -f "${source}_${TARGET}";done
<SNIP>
*******************************************************************
* _ _ _ *
* | |_| |__ ___ /\ /\__ _ _ ____ _____ ___| |_ ___ _ __ *
* | __| _ \ / _ \ / /_/ / _` | '__\ \ / / _ \/ __| __/ _ \ '__| *
* | |_| | | | __/ / __ / (_| | | \ V / __/\__ \ || __/ | *
* \__|_| |_|\___| \/ /_/ \__,_|_| \_/ \___||___/\__\___|_| *
* *
* theHarvester 4.0.0 *
* Coded by Christian Martorella *
* Edge-Security Research *
* cmartorella@edge-security.com *
* *
*******************************************************************
[*] Target: facebook.com
[*] Searching Urlscan.
[*] ASNS found: 29
--------------------
AS12578
AS13335
AS13535
AS136023
AS14061
AS14618
AS15169
AS15817
<SNIP>
过程结束后,我们可以提取找到的所有子域,并通过以下命令对其进行排序:
Tanin@htb[/htb]$ cat *.json | jq -r '.hosts[]' 2>/dev/null | cut -d':' -f 1 | sort -u > "${TARGET}_theHarvester.txt"
现在我们可以通过以下方式合并所有被动侦察文件:
Tanin@htb[/htb]$ cat facebook.com_*.txt | sort -u > facebook.com_subdomains_passive.txt
Tanin@htb[/htb]$ cat facebook.com_subdomains_passive.txt | wc -l
11947
Passive Infrastructure Identification
Netcraft甚至可以在不与服务器交互的情况下向我们提供有关服务器的信息,从被动信息收集的角度来看,这是有价值的。我们可以通过访问使用该服务https://sitereport.netcraft.com并进入目标域。
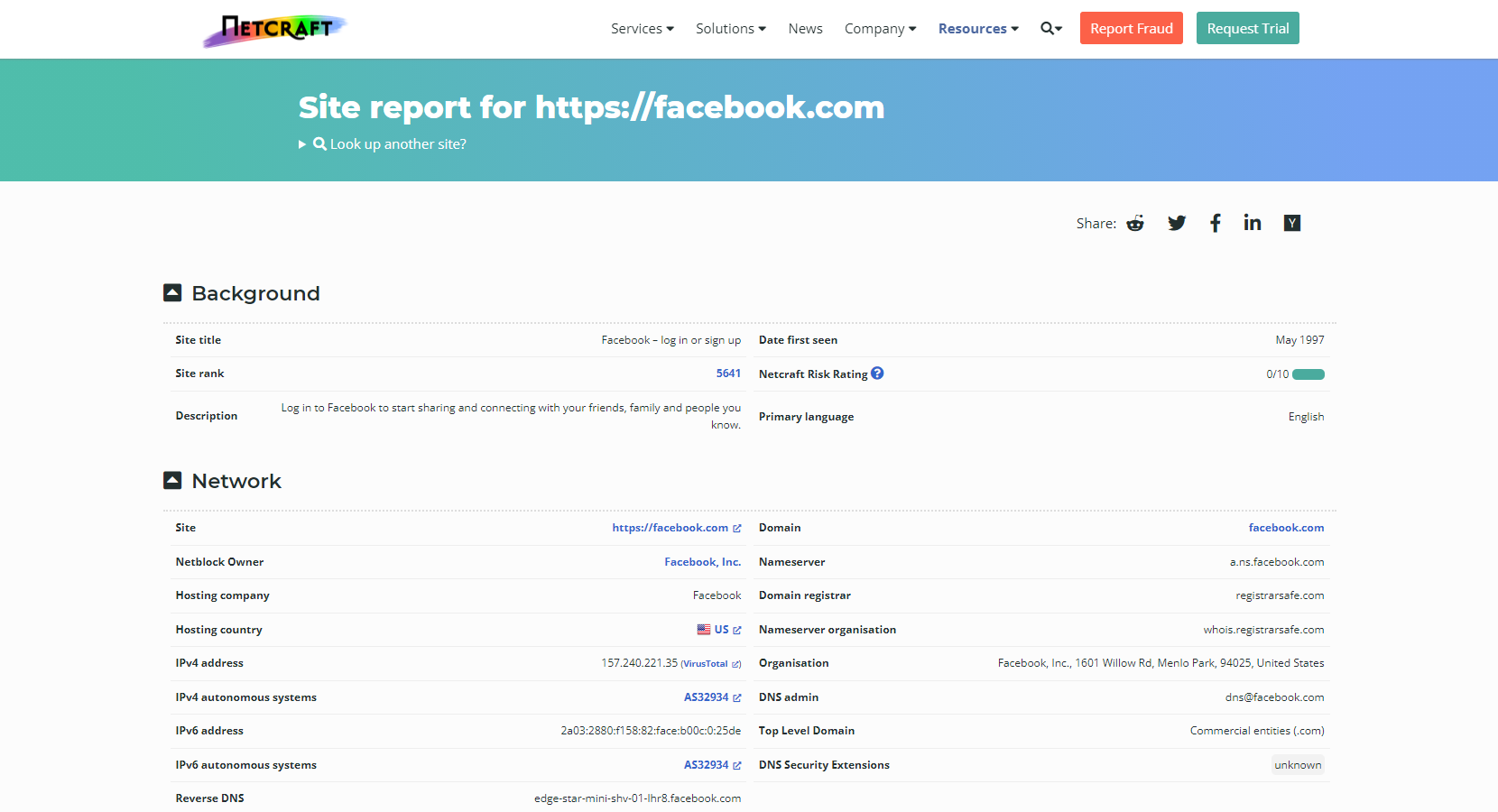
我们需要特别注意使用的最新IP。有时,我们可以在网络服务器被放置在负载均衡器、网络应用程序防火墙或IDS后面之前,从中发现实际的IP地址,从而允许我们在配置允许的情况下直接连接到它。这种技术可能会干扰或改变我们未来的测试活动。
Wayback Machine
我们可以使用 Wayback Machine 访问这些网站的几个版本,以查找在源代码或文件中可能有有趣注释的旧版本,而这些注释不应该存在。此工具可用于在某个时间点查找网站的旧版本。以一个运行WordPress的网站为例。在使用手动方法和自动化工具评估它时,我们可能找不到任何有趣的东西,所以我们使用Wayback Machine搜索它,并找到一个使用特定(现在很脆弱)插件的版本。回到网站的当前版本,我们发现插件没有被正确删除,仍然可以通过wp内容目录访问。然后我们可以利用它在主机上获得远程代码执行和丰厚的奖励。
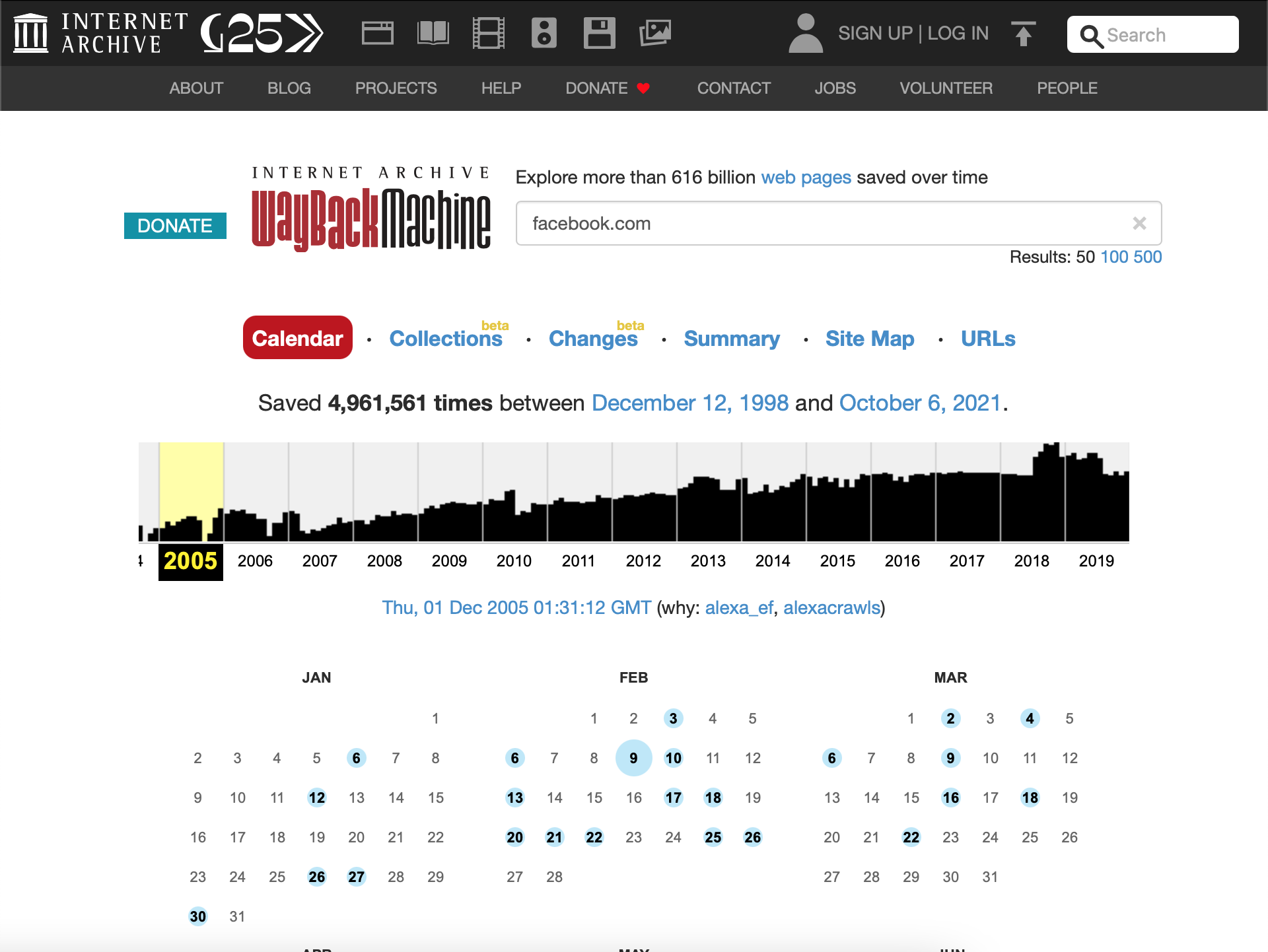
我们还可以使用工具waybackurls来检查Wayback Machine保存的URL,并查找特定的关键字。如果我们在主机上正确设置了Go,我们可以按如下方式安装该工具:
Tanin@htb[/htb]$ go install github.com/tomnomnom/waybackurls@latest
要从域中获取带有获取日期的已爬网URL列表,我们可以在命令中添加-dates开关,如下所示:
Tanin@htb[/htb]$ waybackurls -dates https://facebook.com > waybackurls.txt
Tanin@htb[/htb]$ cat waybackurls.txt
2018-05-20T09:46:07Z http://www.facebook.com./
2018-05-20T10:07:12Z https://www.facebook.com/
2018-05-20T10:18:51Z http://www.facebook.com/#!/pages/Welcome-Baby/143392015698061?ref=tsrobots.txt
2018-05-20T10:19:19Z http://www.facebook.com/
2018-05-20T16:00:13Z http://facebook.com
2018-05-21T22:12:55Z https://www.facebook.com
2018-05-22T15:14:09Z http://www.facebook.com
2018-05-22T17:34:48Z http://www.facebook.com/#!/Syerah?v=info&ref=profile/robots.txt
2018-05-23T11:03:47Z http://www.facebook.com/#!/Bin595
如果我们想访问特定的资源,我们需要将URL放在搜索菜单中,并导航到创建快照的日期。如前所述,Wayback Machine是一种方便的工具,不应被忽视。它很可能导致我们发现被遗忘的资产、页面等,从而发现缺陷。