Overview
简而言之,缓冲区溢出是由不正确的程序代码引起的,CPU无法正确处理过多的数据,因此可能会操纵CPU的处理。例如,假设有太多数据被写入到不受限制的保留内存缓冲区或堆栈中。在这种情况下,特定的寄存器将被覆盖,这可能允许代码被执行。
缓冲区溢出可能导致程序崩溃、损坏数据或损坏程序运行时的数据结构。最后一种可以用任意数据覆盖特定程序的返回地址,使攻击者能够以易受缓冲区溢出影响的进程的权限执行命令,从而通过传递任意机器代码。此代码通常旨在让我们更方便地访问系统,以便将其用于自己的目的。这种缓冲区在普通服务器中溢出,互联网蠕虫也会利用客户端软件。
Unix系统上一个特别流行的目标是root访问,它赋予我们所有人访问系统的权限。然而,正如人们经常误解的那样,这并不意味着“仅”导致标准用户权限的缓冲区溢出是无害的。如果您已经拥有用户权限,那么获得令人垂涎的root访问权限通常会容易得多。
缓冲区溢出,除了编程疏忽之外,主要是由基于冯·诺依曼体系结构的计算机系统造成的。
缓冲区溢出的最重要原因是使用的编程语言不会自动监控内存缓冲区或堆栈的限制,以防止(基于堆栈的)缓冲区溢出。其中包括C和C++语言,它们强调性能,不需要监控。
由于这个原因,开发人员被迫在编程代码中自己定义这些区域,这会多次增加漏洞。出于测试目的或由于疏忽,这些区域通常未定义。即使它们用于测试目的,在开发过程结束时也可能被忽略。
但是,并不是每个应用程序环境都可能出现缓冲区溢出的情况。例如,由于Java处理内存管理的方式,独立的Java应用程序与其他应用程序相比不太可能。Java使用“垃圾收集”技术来管理内存,这有助于防止缓冲区溢出的情况。
Stack-Based Buffer Overflow
内存异常是操作系统对现有软件中的错误或在执行这些软件时的反应。这是过去十年中程序流中大多数安全漏洞的原因。使用C或C++等低抽象语言编程时,由于疏忽,经常会发生编程错误,导致缓冲区溢出。 这些语言几乎直接编译成机器代码,与Java或Python等高度抽象的语言不同,它们运行的操作系统几乎没有控制结构。缓冲区溢出是指允许数据过大而无法放入操作系统内存中不够大的缓冲区,从而溢出该缓冲区的错误。由于这种错误处理,被执行程序的其他函数的内存被覆盖,可能会产生安全漏洞。 这样的程序(二进制文件)是存储在数据存储介质上的通用可执行文件。这种可执行二进制文件有几种不同的文件格式。例如,可移植可执行文件格式(PE)在Microsoft平台上使用。 可执行文件的另一种格式是可执行文件和链接格式(ELF),几乎所有现代UNIX变体都支持它。如果链接器加载这样一个可执行的二进制文件,并且程序将被执行,则相应的程序代码将被加载到主存储器中,然后由CPU执行。 程序在初始化和执行期间将数据和指令存储在内存中。这些是显示在执行的软件中或由用户输入的数据。特别是对于预期的用户输入,必须通过保存输入预先创建缓冲区。 这些指令用于对程序流进行建模。除其他外,返回地址存储在存储器中,该存储器引用其他存储器地址,从而定义程序的控制流。如果使用缓冲区溢出故意覆盖此类返回地址,则攻击者可以通过使返回地址引用另一个函数或子例程来操纵程序流。此外,还可以跳回到先前由用户输入引入的代码。
当程序被调用时,部分被映射到进程中的段,并且段被加载到内存中,如ELF文件所述。
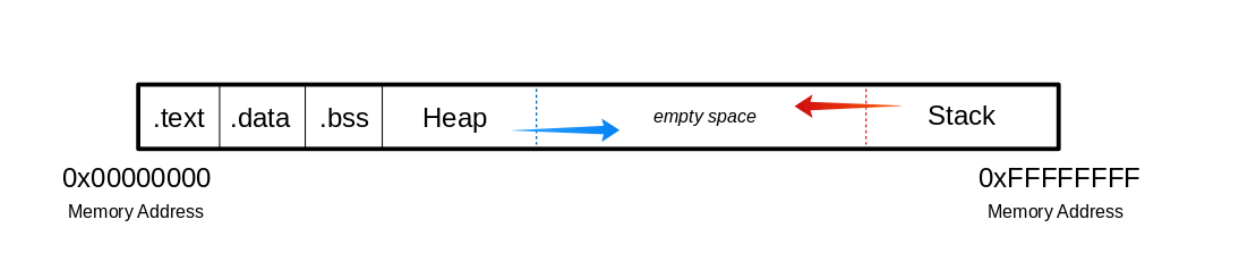
. text: 部分包含程序的实际汇编指令。此区域可以是只读的,以防止进程意外修改其指令。任何写入该区域的尝试都将不可避免地导致分段错误。
.data: 部分包含由程序显式初始化的全局变量和静态变量。
.bss: 一些编译器和链接器使用.bss部分作为数据段的一部分,该数据段包含完全由0位表示的静态分配变量。
堆栈内存是一种后进先出的数据结构,其中存储了返回地址、参数以及帧指针,具体取决于编译器选项。C/C++局部变量存储在这里,您甚至可以将代码复制到堆栈中。堆栈是RAM中定义的区域。链接器保留这个区域,通常将堆栈放在全局变量和静态变量上方RAM的较低区域。内容通过堆栈指针访问,该指针在初始化期间设置为堆栈的上端。在执行过程中,堆栈中分配的部分向下扩展到较低的内存地址。 现代内存保护(DEP/ASLR)可以防止缓冲区溢出造成的损坏。DEP(数据执行保护),将内存区域标记为“只读”。只读内存区域是存储一些用户输入的地方(例如:堆栈),因此DEP背后的想法是防止用户将外壳代码上传到内存,然后将指令指针设置为外壳代码。黑客开始利用ROP(Return-Oriented Programming)来绕过这一点,因为它允许他们将外壳代码上传到可执行空间,并使用现有的调用来执行它。使用ROP,攻击者需要知道存储东西的内存地址,因此,针对它的防御措施是实现ASLR(地址空间布局随机化),它将所有东西存储在哪里随机化,从而使ROP更加困难。 用户可以通过泄露内存地址绕过ASLR,但这会降低漏洞利用的可靠性,有时甚至不可能。例如,“Freefloat FTP服务器”在Windows XP(DEP/ASLR之前)上很难利用。然而,如果应用程序在现代Windows操作系统上运行,则存在缓冲区溢出,但由于DEP/ASLR,目前利用缓冲区溢出并不容易,因为没有已知的方法泄漏内存地址。
Vulnerable Program
我们现在编写一个名为bow.C的简单C程序,该程序带有一个称为strcpy()的易受攻击的函数。
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int bowfunc(char *string) {
char buffer[1024];
strcpy(buffer, string);
return 1;
}
int main(int argc, char *argv[]) {
bowfunc(argv[1]);
printf("Done.\n");
return 1;
}
现代操作系统具有针对此类漏洞的内置保护,如地址空间布局随机化(ASLR)。为了学习缓冲区溢出利用的基本知识,我们将禁用以下内存保护功能:
student@nix-bow:~$ sudo su
root@nix-bow:/home/student# echo 0 > /proc/sys/kernel/randomize_va_space
root@nix-bow:/home/student# cat /proc/sys/kernel/randomize_va_space
student@nix-bow:~$ gcc bow.c -o bow32 -fno-stack-protector -z execstack -m32
student@nix-bow:~$ file bow32 | tr "," "\n"
bow: ELF 32-bit LSB shared object
Intel 80386
version 1 (SYSV)
dynamically linked
interpreter /lib/ld-linux.so.2
for GNU/Linux 3.2.0
BuildID[sha1]=93dda6b77131deecaadf9d207fdd2e70f47e1071
not stripped
Vulnerable C Functions
strcpygetssprintfscanfstrcat- …
GDB Introductions
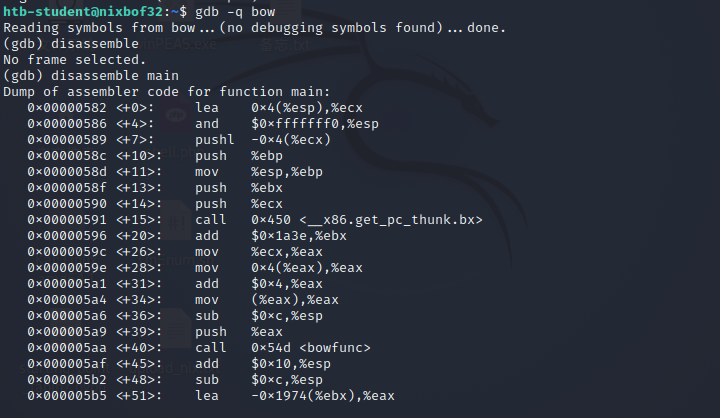
或称GNU调试器,是GNU项目开发的Linux系统的标准调试器。它已经移植到许多系统,并支持编程语言C、C++、Objective-C、FORTRAN、Java等。 GDB为我们提供了常见的可跟踪特性,如断点或堆栈跟踪输出,并允许我们干预程序的执行。例如,它还允许我们操作应用程序的变量,或者独立于程序的正常执行来调用函数。 我们使用GNU调试器(GDB)在汇编程序级别查看创建的二进制文件。一旦我们用GDB执行了二进制程序,我们就可以反汇编程序的主要功能。
GDB - AT&T Syntax
student@nix-bow:~$ gdb -q bow32
Reading symbols from bow...(no debugging symbols found)...done.
(gdb) disassemble main
Dump of assembler code for function main:
0x00000582 <+0>: lea 0x4(%esp),%ecx
0x00000586 <+4>: and $0xfffffff0,%esp
0x00000589 <+7>: pushl -0x4(%ecx)
0x0000058c <+10>: push %ebp
0x0000058d <+11>: mov %esp,%ebp
0x0000058f <+13>: push %ebx
0x00000590 <+14>: push %ecx
0x00000591 <+15>: call 0x450 <__x86.get_pc_thunk.bx>
0x00000596 <+20>: add $0x1a3e,%ebx
0x0000059c <+26>: mov %ecx,%eax
0x0000059e <+28>: mov 0x4(%eax),%eax
0x000005a1 <+31>: add $0x4,%eax
0x000005a4 <+34>: mov (%eax),%eax
0x000005a6 <+36>: sub $0xc,%esp
0x000005a9 <+39>: push %eax
0x000005aa <+40>: call 0x54d <bowfunc>
0x000005af <+45>: add $0x10,%esp
0x000005b2 <+48>: sub $0xc,%esp
0x000005b5 <+51>: lea -0x1974(%ebx),%eax
0x000005bb <+57>: push %eax
0x000005bc <+58>: call 0x3e0 <puts@plt>
0x000005c1 <+63>: add $0x10,%esp
0x000005c4 <+66>: mov $0x1,%eax
0x000005c9 <+71>: lea -0x8(%ebp),%esp
0x000005cc <+74>: pop %ecx
0x000005cd <+75>: pop %ebx
0x000005ce <+76>: pop %ebp
0x000005cf <+77>: lea -0x4(%ecx),%esp
0x000005d2 <+80>: ret
End of assembler dump.
在第一列中,十六进制数字表示内存地址。带加号(+)的数字以字节为单位显示内存中的地址跳跃,用于相应的指令。接下来,我们可以看到带有寄存器及其操作后缀的汇编指令(助记符)。当前的语法是AT&T,我们可以通过%和$字符来识别它。
| Memory Address | Address Jumps | Assembler Instruction | Operation Suffixes |
|---|---|---|---|
| 0x00000582 | <+0>: | lea | 0x4(%esp),%ecx |
| 0x00000586 | <+4>: | and | $0xfffffff0,%esp |
| … | … | … | … |
Intel语法使分解后的表示更易于阅读,我们可以通过在GDB中输入以下命令来更改语法:
GDB - Change the Syntax to Intel
(gdb) set disassembly-flavor intel
(gdb) disassemble main
Dump of assembler code for function main:
0x00000582 <+0>: lea ecx,[esp+0x4]
0x00000586 <+4>: and esp,0xfffffff0
0x00000589 <+7>: push DWORD PTR [ecx-0x4]
0x0000058c <+10>: push ebp
0x0000058d <+11>: mov ebp,esp
0x0000058f <+13>: push ebx
0x00000590 <+14>: push ecx
0x00000591 <+15>: call 0x450 <__x86.get_pc_thunk.bx>
0x00000596 <+20>: add ebx,0x1a3e
0x0000059c <+26>: mov eax,ecx
0x0000059e <+28>: mov eax,DWORD PTR [eax+0x4]
<SNIP>
我们不必不断地手动更改显示模式。我们还可以使用以下命令将其设置为默认语法。
Change GDB Syntax
student@nix-bow:~$ echo 'set disassembly-flavor intel' > ~/.gdbinit
GDB - Intel Syntax
如果我们现在重新运行GDB并反汇编主函数,我们会看到Intel语法。
student@nix-bow:~$ gdb ./bow32 -q
Reading symbols from bow...(no debugging symbols found)...done.
(gdb) disassemble main
Dump of assembler code for function main:
0x00000582 <+0>: lea ecx,[esp+0x4]
0x00000586 <+4>: and esp,0xfffffff0
0x00000589 <+7>: push DWORD PTR [ecx-0x4]
0x0000058c <+10>: push ebp
0x0000058d <+11>: mov ebp,esp
0x0000058f <+13>: push ebx
0x00000590 <+14>: push ecx
0x00000591 <+15>: call 0x450 <__x86.get_pc_thunk.bx>
0x00000596 <+20>: add ebx,0x1a3e
0x0000059c <+26>: mov eax,ecx
0x0000059e <+28>: mov eax,DWORD PTR [eax+0x4]
0x000005a1 <+31>: add eax,0x4
0x000005a4 <+34>: mov eax,DWORD PTR [eax]
0x000005a6 <+36>: sub esp,0xc
0x000005a9 <+39>: push eax
0x000005aa <+40>: call 0x54d <bowfunc>
0x000005af <+45>: add esp,0x10
0x000005b2 <+48>: sub esp,0xc
0x000005b5 <+51>: lea eax,[ebx-0x1974]
0x000005bb <+57>: push eax
0x000005bc <+58>: call 0x3e0 <puts@plt>
0x000005c1 <+63>: add esp,0x10
0x000005c4 <+66>: mov eax,0x1
0x000005c9 <+71>: lea esp,[ebp-0x8]
0x000005cc <+74>: pop ecx
0x000005cd <+75>: pop ebx
0x000005ce <+76>: pop ebp
0x000005cf <+77>: lea esp,[ecx-0x4]
0x000005d2 <+80>: ret
End of assembler dump.
AT&T和Intel语法之间的区别不仅在于指令及其符号的表示方式,还在于指令执行和读取的顺序和方向。 让我们以以下说明为例:
0x0000058d <+11>: mov ebp,esp
对于英特尔语法,我们对示例中的指令有以下顺序:
| Instruction | Destination |
Source |
|---|---|---|
| mov | ebp |
esp |
AT&T语法
| Instruction | Source | Destination |
|---|---|---|
| mov | %esp | %ebp |
practice
target:10.129.42.190
“bowfunc”函数在“main”函数的哪个地址被调用?
CPU Registers
寄存器是CPU的重要组成部分。几乎所有寄存器都提供了少量的存储空间,可以临时存储数据。然而,它们中的一些具有特定的功能。 这些寄存器将分为通用寄存器、控制寄存器和段寄存器。我们需要的最重要的寄存器是通用寄存器。在这些寄存器中,进一步细分为数据寄存器、指针寄存器和索引寄存器。
Data registers
| 32-bit Register | 64-bit Register | Description |
|---|---|---|
EAX |
RAX |
Accumulator is used in input/output and for arithmetic operations 累加器用于输入/输出和算术运算 |
EBX |
RBX |
Base is used in indexed addressing基址用于索引寻址 |
ECX |
RCX |
Counter is used to rotate instructions and count loops计数器用于旋转指令和计数循环 |
EDX |
RDX |
Data is used for I/O and in arithmetic operations for multiply and divide operations involving large values数据用于I/O和涉及大值的乘除运算的算术运算 |
Pointer registers
| 32-bit Register | 64-bit Register | Description |
|---|---|---|
EIP |
RIP |
Instruction Pointer stores the offset address of the next instruction to be executed指令指针存储要执行的下一条指令的偏移地址 |
ESP |
RSP |
Stack Pointer points to the top of the stack堆栈指针指向堆栈顶部 |
EBP |
RBP |
Base Pointer is also known as Stack Base Pointer or Frame Pointer thats points to the base of the stack基址指针也称为堆栈基址指针或帧指针,指向堆栈的基址 |
Stack Frames
由于堆栈从高地址开始,并随着值的添加而向下扩展到低内存地址,因此与指向堆栈顶部的堆栈指针相比,“基指针”指向堆栈的开头(基)。 随着堆栈的增长,它在逻辑上被划分为称为堆栈帧的区域,这些区域为相应的函数分配堆栈中所需的内存。堆栈帧定义了一个具有开始(EBP)和结束(ESP)的数据帧,当调用函数时,该帧被推送到堆栈上。 由于堆栈内存建立在后进先出(LIFO)数据结构上,因此第一步是存储堆栈上的上一个EBP位置,该位置可以在函数完成后恢复。如果我们现在来看bowfunc函数,它在GDB中看起来如下:
(gdb) disas bowfunc
Dump of assembler code for function bowfunc:
0x0000054d <+0>: push ebp # <---- 1. Stores previous EBP
0x0000054e <+1>: mov ebp,esp
0x00000550 <+3>: push ebx
0x00000551 <+4>: sub esp,0x404
<...SNIP...>
0x00000580 <+51>: leave
0x00000581 <+52>: ret
堆栈帧中的EBP是在调用函数时首先设置的,并且包含前一堆栈帧的EBP。接下来,ESP的值被复制到EBP,从而创建一个新的堆栈帧。
(gdb) disas bowfunc
Dump of assembler code for function bowfunc:
0x0000054d <+0>: push ebp # <---- 1. Stores previous EBP
0x0000054e <+1>: mov ebp,esp # <---- 2. Creates new Stack Frame
0x00000550 <+3>: push ebx
0x00000551 <+4>: sub esp,0x404
<...SNIP...>
0x00000580 <+51>: leave
0x00000581 <+52>: ret
然后在堆栈中创建一些空间,将ESP移动到顶部,用于所需和处理的操作和变量。
(gdb) disas bowfunc
Dump of assembler code for function bowfunc:
0x0000054d <+0>: push ebp # <---- 1. Stores previous EBP
0x0000054e <+1>: mov ebp,esp # <---- 2. Creates new Stack Frame
0x00000550 <+3>: push ebx
0x00000551 <+4>: sub esp,0x404 # <---- 3. Moves ESP to the top
<...SNIP...>
0x00000580 <+51>: leave
0x00000581 <+52>: ret
这三条指令代表了所谓的序言。 为了摆脱堆栈框架,相反的做法是结束语。在结束语中,ESP被当前EBP替换,其值被重置为之前在序言中的值。结语相对较短,除了执行它的其他可能性外,在我们的示例中,它使用两个指令执行:
(gdb) disas bowfunc
Dump of assembler code for function bowfunc:
0x0000054d <+0>: push ebp
0x0000054e <+1>: mov ebp,esp
0x00000550 <+3>: push ebx
0x00000551 <+4>: sub esp,0x404
<...SNIP...>
0x00000580 <+51>: leave # <----------------------
0x00000581 <+52>: ret # <--- Leave stack frame
Index registers
| Register 32-bit | Register 64-bit | Description |
|---|---|---|
ESI |
RSI |
Source Index is used as a pointer from a source for string operations 源索引用作字符串操作的源的指针 |
EDI |
RDI |
Destination is used as a pointer to a destination for string operations Destination用作指向字符串操作的目标的指针 |
关于汇编程序表示的另一个重要点是寄存器的命名。这取决于二进制文件的编译格式。我们已经使用GCC以32位格式编译了bow.c代码。现在,让我们将相同的代码编译成64位格式。
student@nix-bow:~$ gcc bow.c -o bow64 -fno-stack-protector -z execstack -m64
student@nix-bow:~$ file bow64 | tr "," "\n"
bow64: ELF 64-bit LSB shared object
x86-64
version 1 (SYSV)
dynamically linked
interpreter /lib64/ld-linux-x86-64.so.2
for GNU/Linux 3.2.0
BuildID[sha1]=9503477016e8604e808215b4babb250ed25a7b99
not stripped
因此,如果我们现在查看汇编代码,我们会发现地址是32位编译二进制的两倍大,并且我们拥有几乎一半的指令。
student@nix-bow:~$ gdb -q bow64
Reading symbols from bow64...(no debugging symbols found)...done.
(gdb) disas main
Dump of assembler code for function main:
0x00000000000006bc <+0>: push rbp
0x00000000000006bd <+1>: mov rbp,rsp
0x00000000000006c0 <+4>: sub rsp,0x10
0x00000000000006c4 <+8>: mov DWORD PTR [rbp-0x4],edi
0x00000000000006c7 <+11>: mov QWORD PTR [rbp-0x10],rsi
0x00000000000006cb <+15>: mov rax,QWORD PTR [rbp-0x10]
0x00000000000006cf <+19>: add rax,0x8
0x00000000000006d3 <+23>: mov rax,QWORD PTR [rax]
0x00000000000006d6 <+26>: mov rdi,rax
0x00000000000006d9 <+29>: call 0x68a <bowfunc>
0x00000000000006de <+34>: lea rdi,[rip+0x9f]
0x00000000000006e5 <+41>: call 0x560 <puts@plt>
0x00000000000006ea <+46>: mov eax,0x1
0x00000000000006ef <+51>: leave
0x00000000000006f0 <+52>: ret
End of assembler dump.
然而,我们将首先看一下易受攻击的二进制文件的32位版本。现在对我们来说最重要的指令是调用指令。调用指令用于调用函数并执行两个操作:
- 它将返回地址推送到堆栈上,使得程序的执行可以在函数成功实现其目标之后继续,
- 它将指令指针(EIP)更改为调用目的地并在那里开始执行。
GDB - Intel Syntax
student@nix-bow:~$ gdb ./bow32 -q
Reading symbols from bow...(no debugging symbols found)...done.
(gdb) disassemble main
Dump of assembler code for function main:
0x00000582 <+0>: lea ecx,[esp+0x4]
0x00000586 <+4>: and esp,0xfffffff0
0x00000589 <+7>: push DWORD PTR [ecx-0x4]
0x0000058c <+10>: push ebp
0x0000058d <+11>: mov ebp,esp
0x0000058f <+13>: push ebx
0x00000590 <+14>: push ecx
0x00000591 <+15>: call 0x450 <__x86.get_pc_thunk.bx>
0x00000596 <+20>: add ebx,0x1a3e
0x0000059c <+26>: mov eax,ecx
0x0000059e <+28>: mov eax,DWORD PTR [eax+0x4]
0x000005a1 <+31>: add eax,0x4
0x000005a4 <+34>: mov eax,DWORD PTR [eax]
0x000005a6 <+36>: sub esp,0xc
0x000005a9 <+39>: push eax
0x000005aa <+40>: call 0x54d <bowfunc> # <--- CALL function
<SNIP>
Endianness
在寄存器和存储器中的加载和保存操作期间,字节以不同的顺序读取。这种字节顺序称为字节序。端性是区分小端格式和大端格式的。 大端序和小端序是关于价的顺序。在大端序中,具有最高化合价的数字最初是。在小端序中,具有最低化合价的数字位于开头。大型机处理器使用big-endian格式,一些RISC体系结构,小型计算机,在TCP/IP网络中,字节顺序也是big-endia格式。 现在,让我们来看一个具有以下值的示例:
- Address:
0xffff0000 - Word:
\xAA\xBB\xCC\xDD
| Memory Address | 0xffff0000 | 0xffff0001 | 0xffff0002 | 0xffff0003 |
|---|---|---|---|---|
| Big-Endian | AA | BB | CC | DD |
| Little-Endian | DD | CC | BB | AA |
当我们必须告诉CPU它应该指向哪个地址时,这对我们以后以正确的顺序输入代码非常重要。